

Un des principes de qualité de code est le Couplage. Ici nous allons essayé de comprendre ce que c'est, pourquoi il faut l'éviter et un aperçu de bonne pratique de conception de code.
Architecture informatique : Le couplage
Le couplage est une (des nombreuses) unité de mesure de qualité de code. Il existe plusieurs type de couplage, ici nous allons surtout nous pencher sur le couplage fort, le pire de tous.
Les différents niveau de couplage
Pour la culture de chacun, wikipedia nous explique les différents niveau de couplage :
- Sans couplage : les composants n'échangent pas d'information.
- Par données : les composants échangent de l'information par des méthodes utilisant des arguments (paramètres) de type simple (nombre, chaîne de caractères, tableau).
- Par paquet : les composants échangent de l'information par des méthodes utilisant des arguments de type composé (structure, classe).
- Par contrôle : les composants se passent ou modifient leur contrôle par changement d'un drapeau (verrou).
- Externe : les composants échangent de l'information par un moyen de communication externe (fichier, pipeline, lien de communication).
- Commun (global) : les composants échangent de l'information via un ensemble de données (variables) commun.
- Par contenu (interne) : les composants échangent de l'information en lisant et écrivant directement dans leurs espaces de données (variables) respectifs.
Le couplage fort c'est quoi ?
Un couplage est dit fort quand plusieurs instances de classes accèdent à la même ressources :
Un exemple basique fournit par wikipedia sur l'interblocage :
Soit deux processus (P1 et P2), le premier processus P1 modifie une ressource R1 qui est utilisée par P2 qui lui même modifie une ressource R2 qui est utilisée par P1. Déjà, juste en lisant ça, on a mal au crane ! Voici un petit schéma du résultat :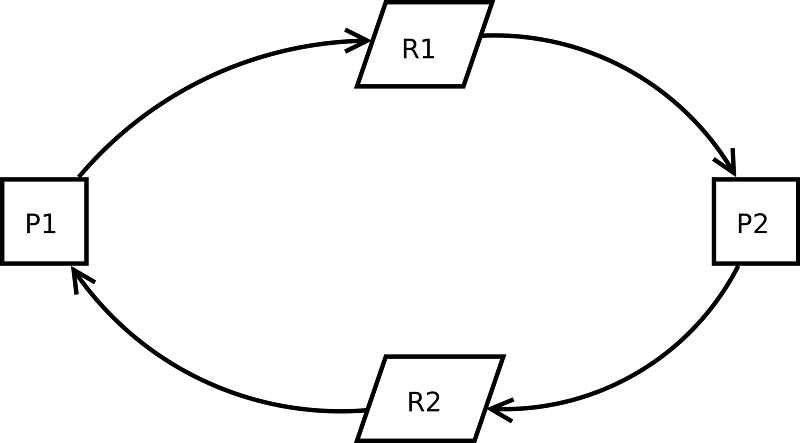
Le problème de cette conception est que la plupart du temps tout va bien se passé, aucun problème a déplorer... Mais il est possible que à un moment, le processus P1 soit en attente du processus P2, lui même en attente du processus P1 (cas C, ci-dessous) : le code est dans une boucle infinie.
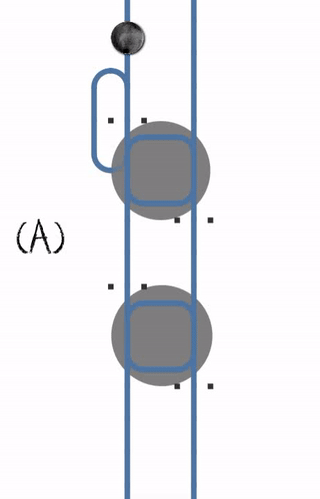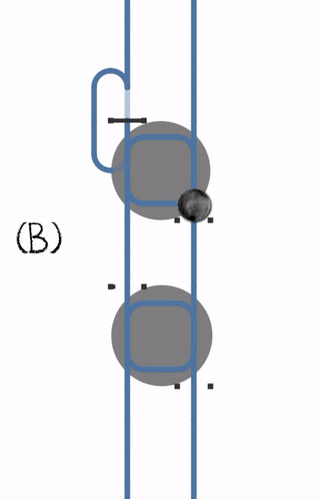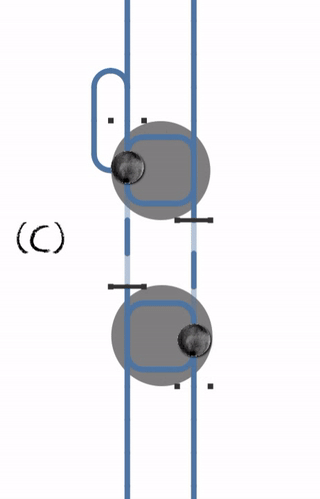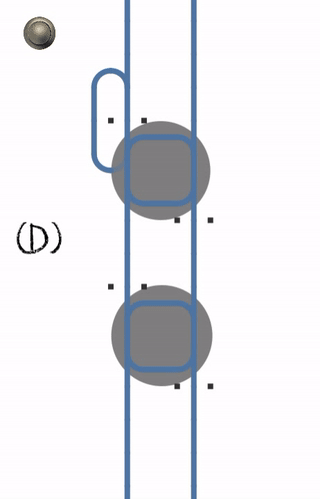
Reconnaître le couplage fort
Une manière simple d'éviter la plupart des couplages fort est le fameux diagramme des classes. Je vais prendre un exemple simple avec une voiture.
- Une voiture possède un moteur.
- Le moteur est reliée à des roues.
- Les roues connaissent la voiture, elle la font avancée
Attention à la 3ème relation, elle va créer un couplage fort ! Ci-dessous le schéma de classe :
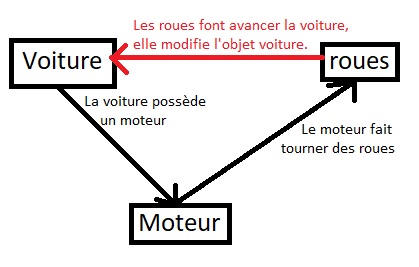
Ici, l'on peut voir que les flèches forment une boucle : Voiture -> Moteur -> Roues -> Voiture. Cette boucle est un couplage fort. Il faut à tout pris éviter cette architecture.
Pour ce faire, dans ce cas simple, l'on peut imaginer que l'information nécessaire à Voiture sera obtenu via une méthode de Moteur, qui elle même récupèrera l'information de Roues. Ce qui est quand même assez lourd. Une autre solution est d'utiliser un type de classe spécifique appelée Interface qui permet d'éviter un couplage fort, ce type d'architecture sera étudier dans de futur tutoriel sur les Design Pattern.
Couplage fort, un indicateur important, une mesure de l'état du code
En un mot comme en mille, un couplage fort signifie au mieux que le code ne peut pas évoluer (impossible de changer un asset du jeu sans détruire le jeu), au pire que le code n'est pas fonctionnel.
Voici un aperçu des problèmes que peut engendré le couplage fort :
- L'antipattern du plat de spaghetti. Il est difficile, voir impossible, de savoir "qui" fait quoi ? C'est à dire qu'il est difficile de savoir quelle classe contient la données, quelle classe l'a modifiées, par quelle méthode l'action a été déclenchée.
- L'abandon de la granularité modulaire du code... Le principe de l'informatique c'est réduire un problème complexe à de nombreux petits problèmes extrêmement simple. Cela permet effectivement de résoudre des problèmes complexes, mais surtout, un bon informaticien est un fainéant, il a donc tout intérêt à pouvoir réutiliser de petit module unitaire de manière indépendante. Ainsi, un même module unique peut permettre de résoudre de nombreux problème plus complexe sans avoir à recoder quoi que se soit.
- En C#, une fuite de mémoire est une faille du garbage collector. Le garbage collector est le système qui s'occupe de libérer la mémoire une fois qu'un objet n'est plus utilisé par votre programme. Dans le cas d'un couplage fort, il est possible que le garbage collector ne libère jamais la mémoire de l'objet inutilisée, avec le temps le programme recréera de nouvelles instances de l'objet et une fois encore ces nouvelles instances ne seront jamais libérée. L'espace en mémoire utilisé par le programme ne cessera jamais de croitre jusqu'au crash de la machine.
- Interblocage, dans le cas d'un programme multithreadé, c'est à dire avec plusieurs processus de calcul simultannés, il est possible qu'une même données requises par deux processus en simultanés entraine le blocage complet du programme.


 0
0

